
Estimating Software Development Time
Agile EstimationWhat is the need for an “Estimate”, because everything is bound to change rite in actuality. Before coming to the need for estimation let us set the context for this discussion. Estimation is nothing, but a human being’s an innate necessity of wanting to predict the future with the term “Accuracy” directly relating to the probability of the expected outcome. In simple terms, we want stuff to happen the way we want and when we want.
But the reality is seldom this simple, because of the randomness of the events that surround us. It is very difficult to predict the probability of every possible outcome with a certain assumed degree of accuracy.
This is where our buddy “Estimate” comes into the picture. In any line of work, an important question that requires an answer on priority is how soon and in what budget a project or work or task can be completed because we wanted it to be completed by yesterday!
Let’s get real. Estimations are required because we have to start somewhere and most importantly, to avoid “Waste”. Waste comes in different forms. It can be Natural Resources, Human Resources, Time, Cost, etc.
“The difference between what I think is valuable and what is valuable creates waste.”
- XP Explained
But how accurately can we estimate the outcome of an event, that is the most relevant and necessary question that is to be asked in Software Development, that too in an Agile environment where change is inevitable, and is expected and accepted.
We have established that we want to estimate because we need to plan ‘Something’, and we would want to minimize ‘Waste’. But how do we estimate and what should we estimate?
Estimation can be broadly classified into two types, “Effort Estimation” and “Cost Estimation” both of which are equally important in an agile software environment.
Effort Estimation:
This translates to the amount of probable time that is to be spent on completing a defined task. The accuracy of this estimate directly depends on the definition of this task.
To quote “Donal Rumsfield”
There are known knowns – there are things we know that we know.
There are known unknowns – that is to say, there are things we know we don’t know.
But there are also unknown unknowns – there are things that we do not know we don’t know.
How much we know about a task and how much we don’t know, and the time spent in knowing the unknowns all put together forms the crux of our estimate in completing the given.
There are many techniques available for estimating the effort. Given below are some of the popular techniques, which are used in effort estimation:
Parametric Estimation:
Parametric estimation is one of the statistical methods to estimate the amount of time required to complete a project. This technique is mainly dependent on the available historical data of an assumed ‘parameter’. The output of a parametric estimate can be classified into two types based on granularity and accuracy: Deterministic and Probabilistic.
A parameter with its assumed correlation to the amount of time taken is determined and is then scaled up to the actual project size. A deterministic result is a certain number or a figure based on such scaling of the correlation. A probabilistic result on the other hand provides a range of estimates over a probability density curve as given below:
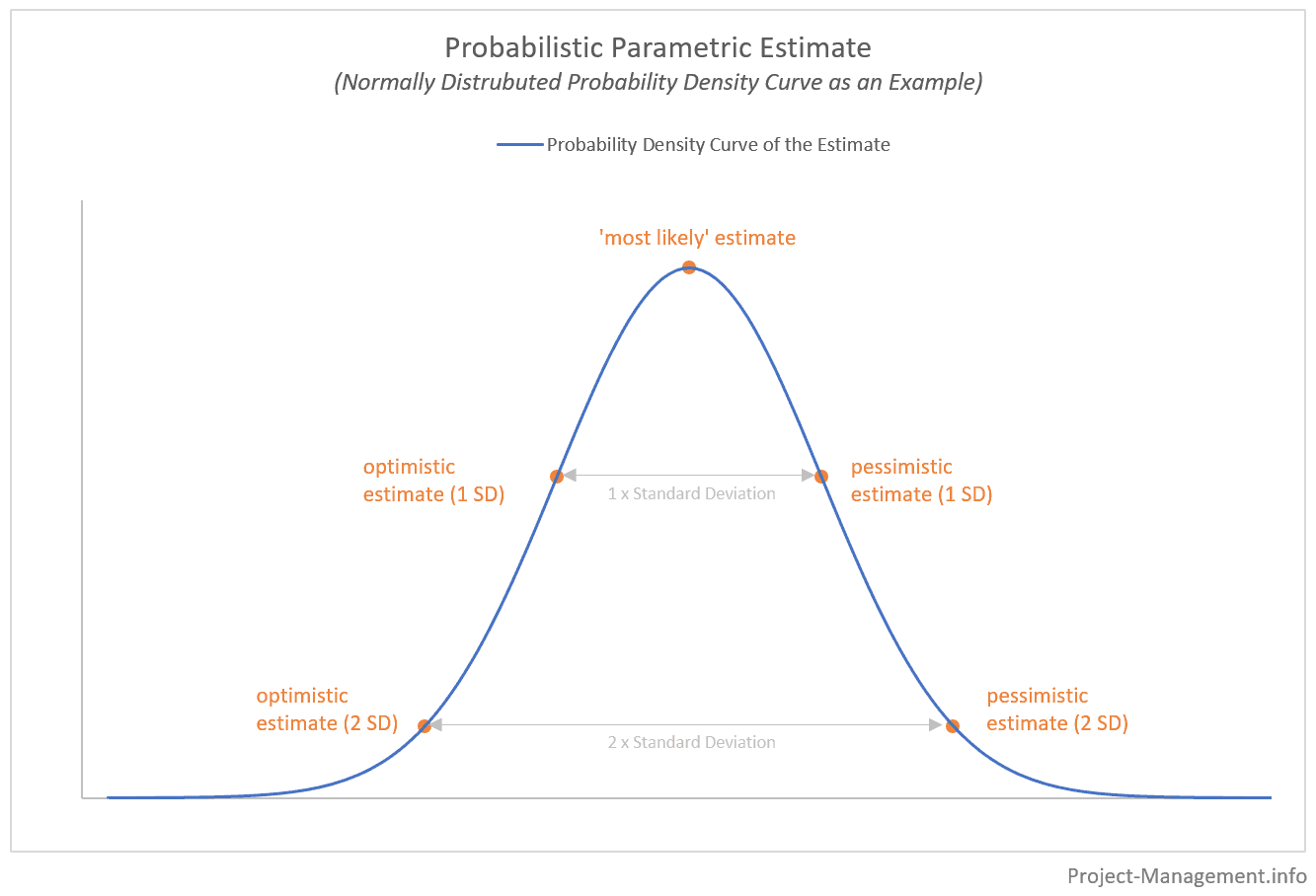
The first step in this technique is to determine the required parameter and the level of accuracy of the estimate. For example, take the method of story point estimation. We know that one story point is assigned to a task or a feature, which is the most basic work that can be completed in a given time. Keeping such a story as a reference, all the other stories can be assigned points. This means we can correlate the time taken to complete a task and the story point, which is EP = Aold/Pold * Pcurr.
where EP is the parametric estimate, Aold is the historic average time taken, Pold is the historic value of the parameter, Pcurr is the current value of the parameter in the current project
So, if a team used to complete 50 story points in a 3-week sprint for a project that is similar to the current project, and our current project sprint length is 2 weeks, then our EP will be 50/3 * 2 = 33 story points. The emphasis is always on the parameter, which in our case is the sprint length.
Calculating multiple parametric estimates with different sprint lengths and story points for a project can help narrow down the variance and standard deviation. This in turn can be used to approximate how many of these estimates fall under one standard deviation from the mean, which is the most likely estimate for the current project.
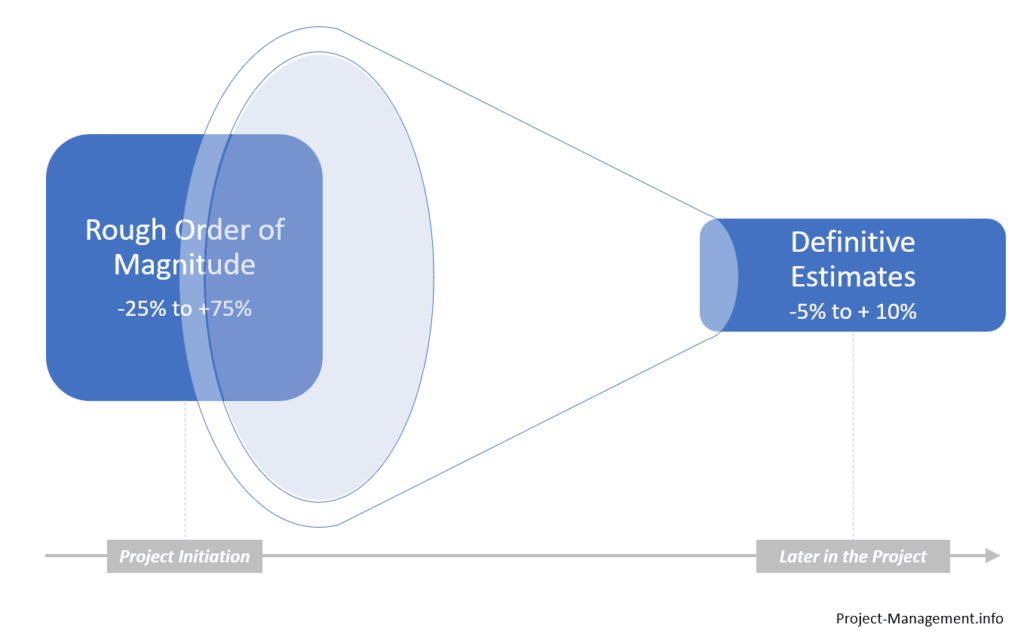
Rough Order of Magnitude (ROM)
As the name suggests, this technique provides a quick rough estimate on an assumed parameter and throughout the project, the estimate becomes more definitive within the boundaries of accuracy. The initial estimate gives us a wide range of accuracy without any definitive results based on the parameter, which is the ROM Estimate. Assuming we require an accuracy range of 25-75% the boundaries can be calculated as given below. Upper Boundary = ROMEstimate * (1+75%) Lower Boundary = ROMEstimate * (1-25%)
When a project is in its initial phases, the accuracy of our estimates tends to be vague as we accommodate for many unknowns, but as we progress along the project the estimates tend to be more definitive with lesser deviation in terms of accuracy.
PERT:
PERT, also known as Project Evaluation Review Technique is another statistical estimation technique that incorporates all the uncertainties in the estimates. It is based on the idea that any task can have a broad range of estimates depending on unknowns. It is divided likely into the following points:
O = Optimistic Estimate M = Most-likely Estimate P = Pessimistic Estimate
The estimate E can be defined as:
E = (O + (4*M) + P)/6
Mean PERT Average is calculated by giving more weightage to Most Likely Estimate.
We can also calculate the variance, which is the level of volatility of the required time to complete the project as follows:
σ = ((P-O)/M)2
which is basically the variance from our most likely estimate.
Weighted Average:
A weighted average is a simple and quick way to estimate wherein we assign weights to a parameter of the estimate. For example, if we consider the optimistic, pessimistic, and most likely outcomes and assign weights to each outcome based on a probability percentage assuming our estimates are story points then the weighted average will be as follows:
Optimistic = 50 with a likely outcome of 70% Pessimistic = 40 with a likely outcome of 40% Most Likely = 45 with a likely outcome of 30%
Weighted average = (50*70%)+(40*40%)+(45*30%) / 3
Delphi:
Unlike statistical methods, Delphi is a qualitative estimation technique where it mainly depends on experts working on the project. There are multiple rounds of questionnaires along the lines of effort and estimate, and in each round, everything is collated and summarized. The next round of questions is based on the disagreements of the previous rounds.
This brings us to a very important question. Considering all things agile, is it really necessary to spend time and resources on estimating when you know things are bound to change? My personal opinion is that it is more relevant to have these figures at your disposal owing to the dynamic nature of software development. We know that regardless of extensive research and statistical analysis, estimates change. Nevertheless, these estimates help us in a very important aspect of software development i.e., when the time taken to complete a project is estimated on the lower end, the team involved in the development process will get overworked resulting in a compromise on the quality of delivery. It will also hamper the work-life balance of the team members, which is quintessential to any thriving team. On the other hand, if the estimate turns out to be on the higher end, then it becomes very difficult to secure the interests of the client, which can have a devastating effect on the project itself.
This brings us to the psychological need for estimates. Trust: The less you trust the team the more you feel the need to get estimates (I would like to know your thoughts on this one) Also, how the long cycle times in releases tend to change the estimates and thus depletes trust
On a contrasting note, a team that is continuously delivering smaller chunks frequently does not require any estimates. No Estimate: Recently, how high-functioning teams have started working totally without estimates because they keep the batch size extremely small. They slice the stories into a very thin quantum of work and they add value on daily bases, if not more frequently.