
Decode LLM Quality - Eval Testing and Benchmarking LLMs: An Evaluation Guide
AI TDD Eval TestingOur Journey with LLM Evaluation Frameworks: From Eval.ai to a DeepEval-LangSmith Hybrid Approach
"What gets measured gets improved." - Peter Drucker
Introduction
In the rapidly evolving landscape of Large Language Models (LLMs), ensuring the quality and reliability of model outputs isn’t just good practice-it’s essential. As our team embarked on building production-grade LLM applications, we quickly realized that robust evaluation frameworks would make the difference between mediocre and exceptional AI experiences.
This blog post chronicles our evaluation journey—from our initial steps with Eval.ai through our transition to DeepEval, and finally to our current hybrid approach combining DeepEval’s synthetic data generation capabilities with LangSmith’s comprehensive observability.
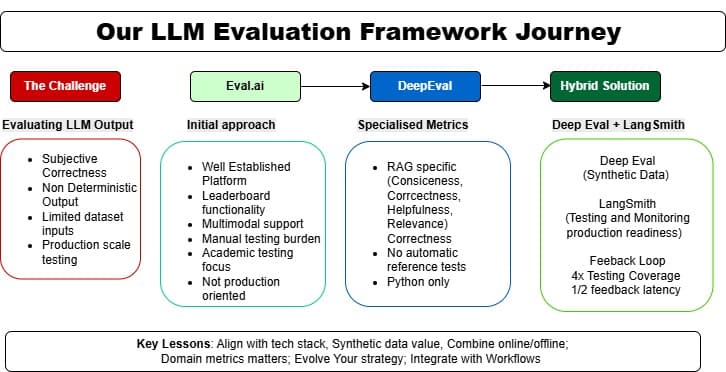
The Challenge: Evaluating LLM Outputs at Scale
Before diving into the tools, let’s frame the challenge we faced. Evaluating LLM outputs differs significantly from traditional software testing because:
-
Correctness is often subjective — What makes a response "good" can vary based on context
-
Outputs are non-deterministic — The same prompt can yield different responses
-
Multidimensional quality — Responses need to be evaluated across dimensions like relevance, factuality, helpfulness, and safety
-
Testing at production scale — Manual evaluation quickly becomes unsustainable
Our Initial Approach: Eval.ai
We started our evaluation journey with Eval.ai, a platform designed primarily for ML researchers and competition organizers.
What We Liked About Eval.ai
-
Well-established platform with support for both automatic and human evaluations
-
Leaderboard functionality for comparing different model variants
-
Support for multimodal evaluation
The Limitations We Encountered
-
Too many manual tasks required for routine testing
-
Primarily designed for academic challenges rather than production deployment
-
Limited integration options with our existing TypeScript codebase
-
Not optimized for LLM-specific evaluation metrics such as hallucination detection
After several sprints of struggling with these limitations, we knew we needed a more specialized solution for LLM evaluation.
Discovering DeepEval: LLM-Specific Testing
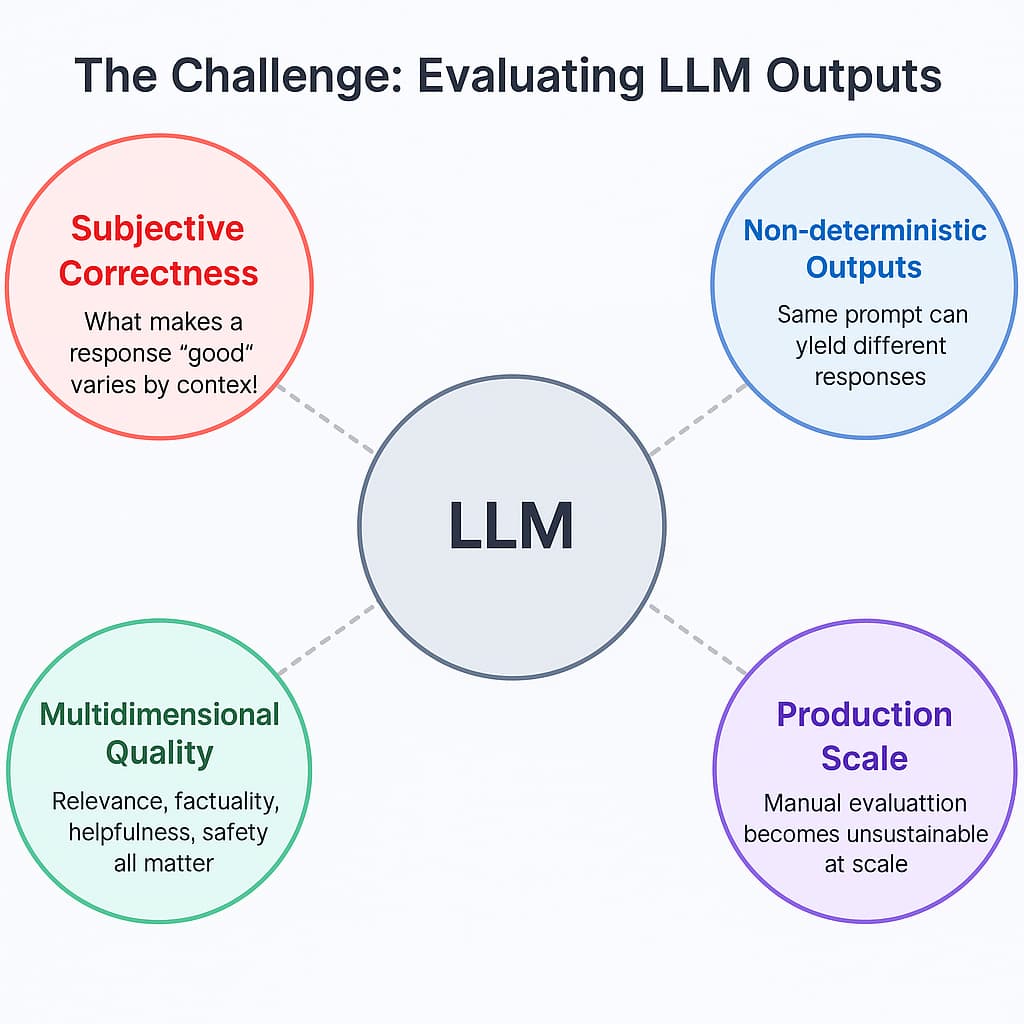
Our search led us to DeepEval, a framework specifically built for evaluating generative AI outputs with a focus on semantic quality and factuality.
What Drew Us to DeepEval
DeepEval offered specialized metrics that aligned perfectly with our RAG (Retrieval-Augmented Generation) implementation:
RAG-Specific Metrics
-
Answer Relevancy: How well does the response address the query?
-
Faithfulness: Does the response stick to the facts in the provided context?
-
Contextual Relevancy: Is the retrieved context relevant to the query?
-
Contextual Precision & Recall: How precise and comprehensive is the context selection?
Chatbot Metrics
-
Conversational G-Eval: Overall quality of conversational responses
-
Knowledge Retention: Ability to maintain context across a conversation
-
Role Adherence: Consistency with defined persona or role
-
Conversation Completeness & Relevancy: How thoroughly and relevantly queries are addressed
Agent Metrics
-
Tool Correctness: Proper use of available tools
-
Task Completion: Success in accomplishing requested tasks
The DeepEval Workflow
DeepEval implements test cases representing atomic interactions with your LLM application, scored using various LLM-as-a-judge techniques:
-
QAG (Question-Answer Generation)
-
DAG (Deep Acyclic Graphs)
-
G-Eval methodologies

The TypeScript Challenge
DeepEval proved to be an excellent evaluation framework, but we faced one significant challenge: our production system was built in TypeScript, while DeepEval is Python-based. This language mismatch led us to explore a hybrid approach.
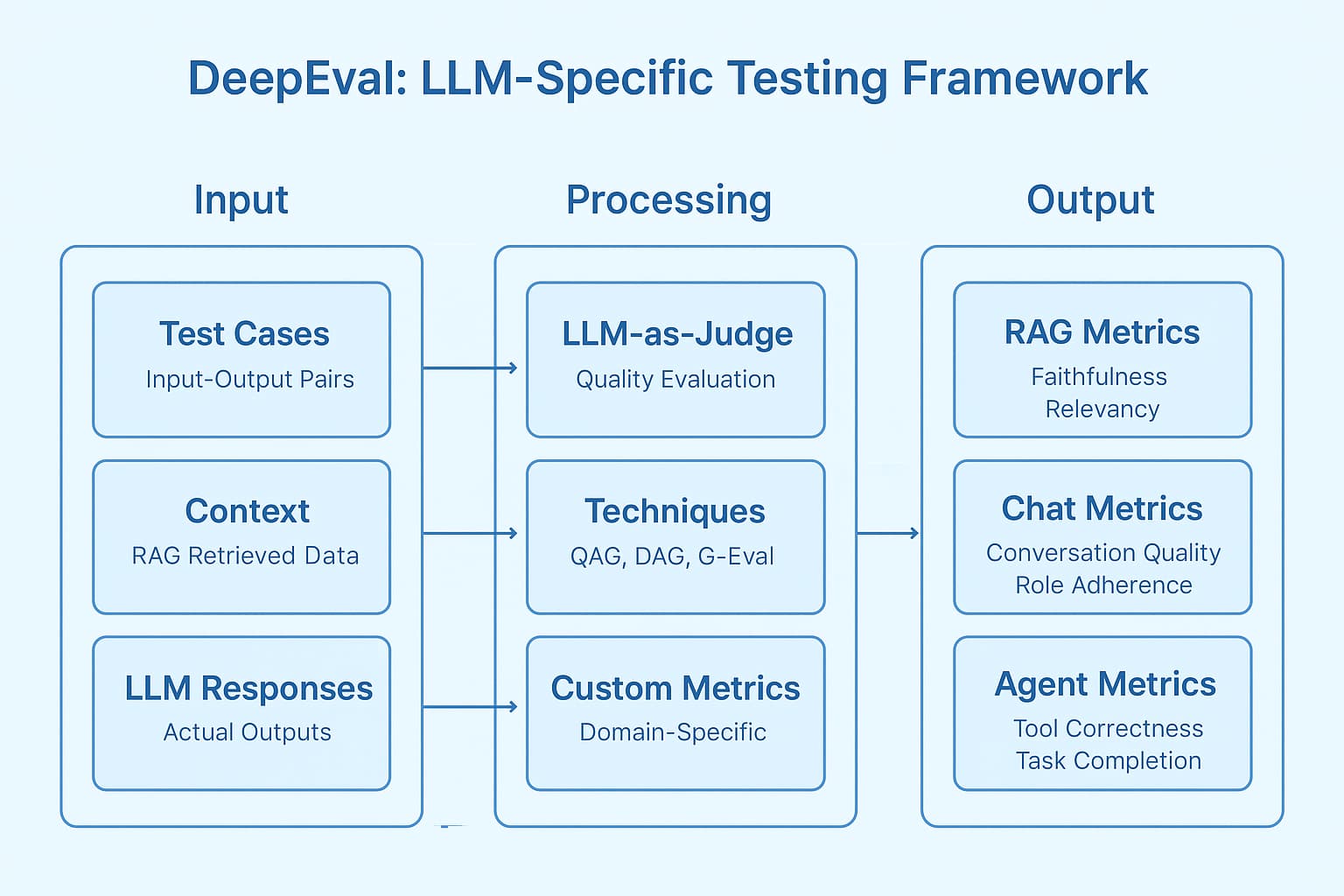
Our Hybrid Solution: DeepEval + LangSmith
Rather than completely switching frameworks again, we developed a hybrid approach leveraging the strengths of both DeepEval and LangSmith.
How Our Hybrid Approach Works:
-
Use DeepEval for synthetic data generation
a. Leverage DeepEval's capabilities to generate diverse, high-quality test cases
b. Create "golden datasets" of input-context-expected output triplets
-
Implement testing and monitoring in LangSmith
a. Feed synthetic data into LangSmith for continuous evaluation
b. Track model performance and quality metrics in production
-
Maintain a feedback loop
a. Identify failure modes in LangSmith
b. Generate new synthetic test cases with DeepEval targeting those failure modes
LangSmith Benefits in Our Hybrid Approach
LangSmith brings several advantages to our hybrid evaluation system:
| Feature | Benefit |
|---|---|
| Full LLMOps Lifecycle | Combines evaluation, observability, and dataset management |
| Tracing | Captures full traces of LLM chains and intermediate steps |
| Production Integration | Monitors live traffic with minimal overhead |
| Dataset Management | Organizes examples for evaluation and fine-tuning |
| TypeScript SDK | Seamless integration with our existing codebase |
Results and Insights
After implementing our hybrid approach, we observed several significant improvements:
-
Testing Coverage: 4x increase in test coverage across different query types
-
Evaluation Speed: 70% reduction in time needed to evaluate new model versions
-
Issue Detection: Identified subtle hallucination patterns that went undetected with manual testing
-
Production Monitoring: Real-time alerts when metric thresholds are breached
Comparative Analysis: Evaluation Frameworks
To help others facing similar challenges, here’s our comparison of the main frameworks we explored:
| Aspect | Eval.ai | DeepEval | LangSmith | Our Hybrid Approach |
|---|---|---|---|---|
| Purpose | Model benchmarking & competitions | LLM-specific evaluation | Full LLMOps lifecycle | Comprehensive testing & monitoring |
| Language | Python, Web interface | Python | TypeScript/Python | Python + TypeScript |
| Synthetic Data | Limited | Strong | Limited | Strong |
| Production Monitoring | No | Yes | Yes | Yes |
| TypeScript Support | No | No | Yes | Yes |
| RAG-specific Metrics | No | Yes | Basic | Yes |
| Integration Effort | High | Medium | Low | Medium |
Lessons Learned
Our journey through these evaluation frameworks taught us several valuable lessons:
-
Match the framework to your tech stack: The language your evaluation framework uses should align with your production codebase.
-
Synthetic data is invaluable: Generating diverse, realistic test cases is essential for comprehensive evaluation.
-
Combine offline and online evaluation: Pre-deployment testing and production monitoring are both necessary.
-
Domain-specific metrics matter: Generic metrics don't capture the nuances of specialized applications like RAG systems.
-
Evolve your evaluation strategy: As your LLM applications mature, your evaluation approach should evolve as well.
What’s Next?
As we continue refining our evaluation approach, we're exploring several promising directions:
-
Behavioral testing: Developing more sophisticated adversarial examples
-
Human-in-the-loop validation: Selectively incorporating human feedback
-
Continuous learning: Using evaluation failures as fine-tuning examples
-
Multi-modal evaluation: Extending our framework to handle image and audio inputs
Conclusion
The journey from Eval.ai to our current hybrid DeepEval-LangSmith approach reflects the rapid evolution of LLM evaluation. By leveraging DeepEval’s synthetic data generation capabilities and LangSmith’s comprehensive observability, we’ve built an evaluation framework that supports our TypeScript codebase while providing robust, multi-dimensional quality assessment.
For teams building production LLM systems, we recommend exploring this hybrid approach—it combines the best of specialized evaluation techniques with practical integration into existing workflows and technology stacks.
Remember: in the world of LLMs, you can’t improve what you don’t measure, and you can’t trust what you don’t test.
How is your team handling LLM evaluation? We’d love to hear about your approaches and challenges in the comments below!