Which Unique Identifier is right for you?
Software CraftsmanshipWhen was the last time you considered unique identifiers (IDs) for your projects? There are many options available, each with its pros and cons. In this article, we’ll explore some popular choices to help you decide which one is best for your next project.
Choosing the right unique identifier is crucial. We want our IDs to be reliable, scalable, and performant. We’ll break down some well-known IDs: UUID, ULID, CUID, and NanoID, examining their strengths and weaknesses. By the end, you’ll be able to choose the right identifier for your needs.
UUID (Universally Unique Identifier)
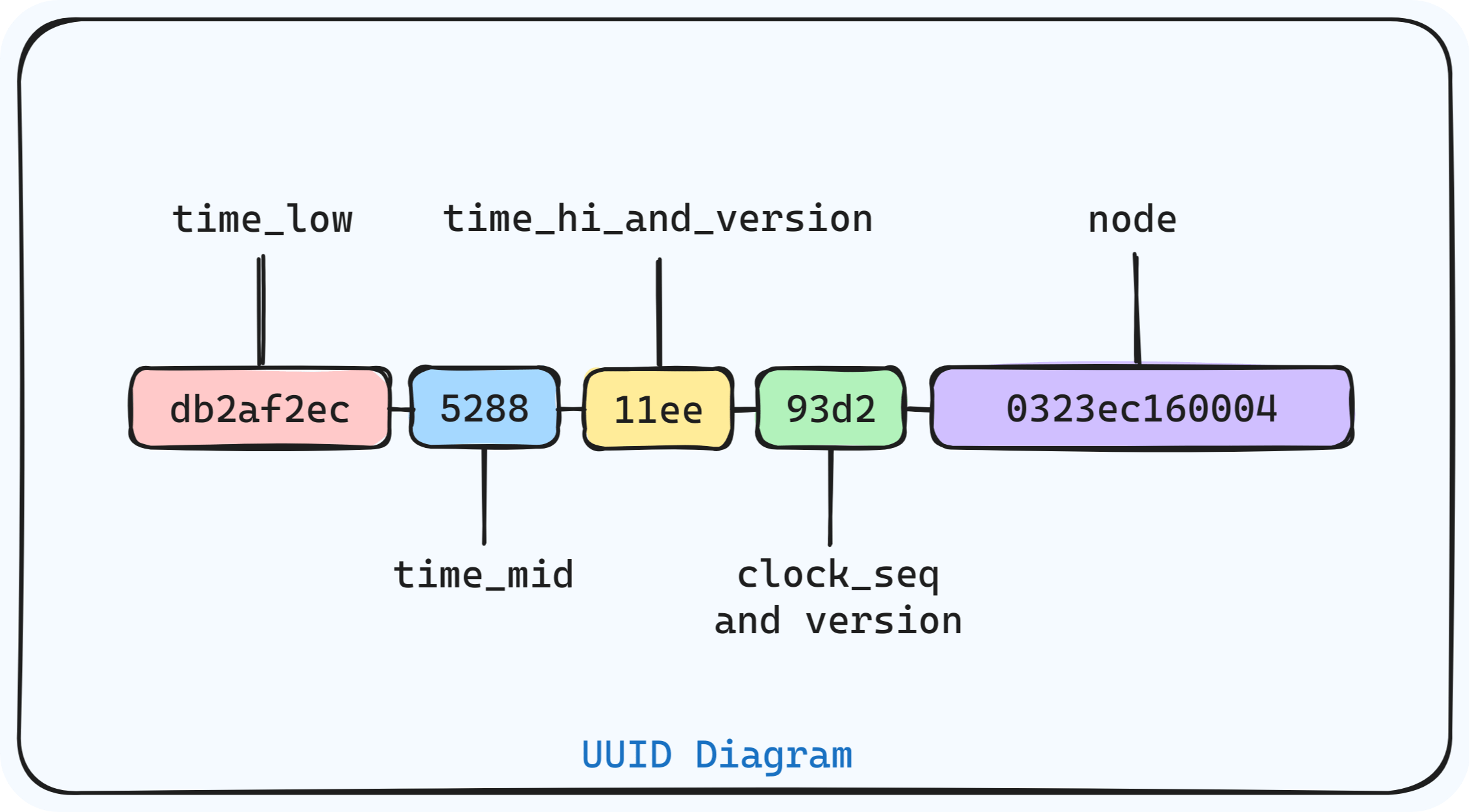
UUIDs are widely used to generate unique IDs for objects, often as primary keys. UUIDs have several versions, with version 4 being the most common.
Pros
- Independently generated without needing knowledge of other systems.
- Reduces single points of failure in distributed systems as it doesn’t depend on centralized service.
- Simple and works well for small projects.
- Supported by databases like PostgreSQL (
uuid_generate_v4()), MySQL (UUID()), and more.
Cons
- Can impact insert performance in MySQL (MySQL uses B+ tree which requires frequent re-balancing aka page splitting. With randomness, it takes significantly longer than usual to perform tree re-balancing)
- Takes up more space (128 bits) than traditional integer-based IDs.
- Not naturally ordered, making sequential ordering difficult.
ULID (Universally Unique Lexicographically Sortable Identifier)
ULID addresses some limitations of UUID. It’s a 26-character ID composed of a 48-bit timestamp and 80 bits of randomness, URL-safe (no special characters), and case insensitive.
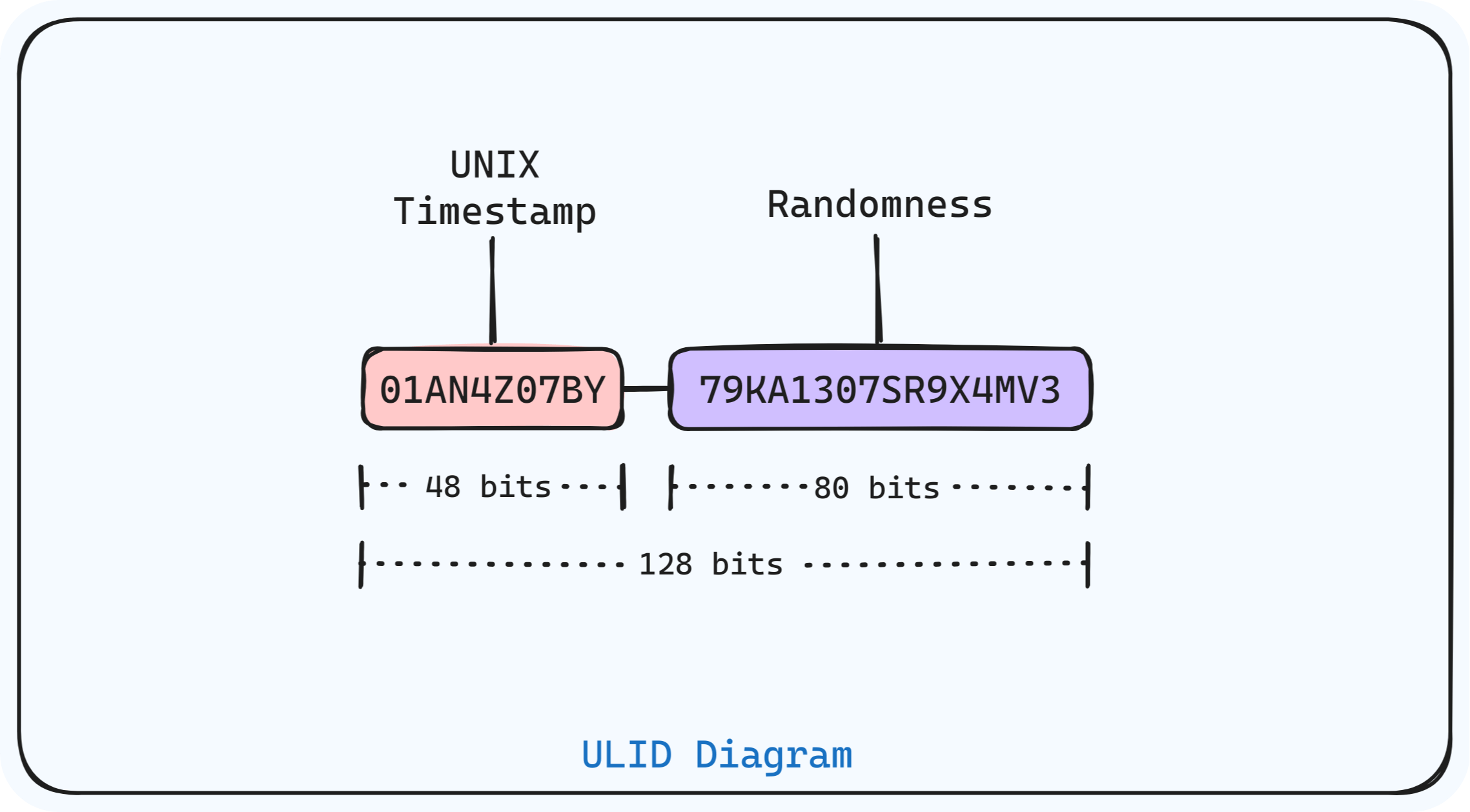
It uses a UNIX timestamp in milliseconds and a cryptographically secure source of randomness to generate the second part of the ULID (randomness).
Pros
- Lexicographical sorting is the biggest highlight of ULID, allowing IDs to be sorted in their natural order.
- More readable and compact than UUID, saving storage space.
- Ideal solution if there is a need for sequentiality or order.
Cons
- Randomness is limited in the timestamp, so it is possible to generate multiple IDs within the same millisecond.
- Due to limited randomness, it doesn’t guarantee a collision-resistant solution.
- Not widely adopted due to compatibility issues with UUID systems.
CUID (Collision-Resistant Unique Identifier)
CUIDs are designed for high collision resistance and performance, with a default length of 24 characters but configurable up to 32 characters.
To react 50% chance of collision, you’d need to generate roughly 4,000,000,000,000,000,000 IDs. Which is quite huge.
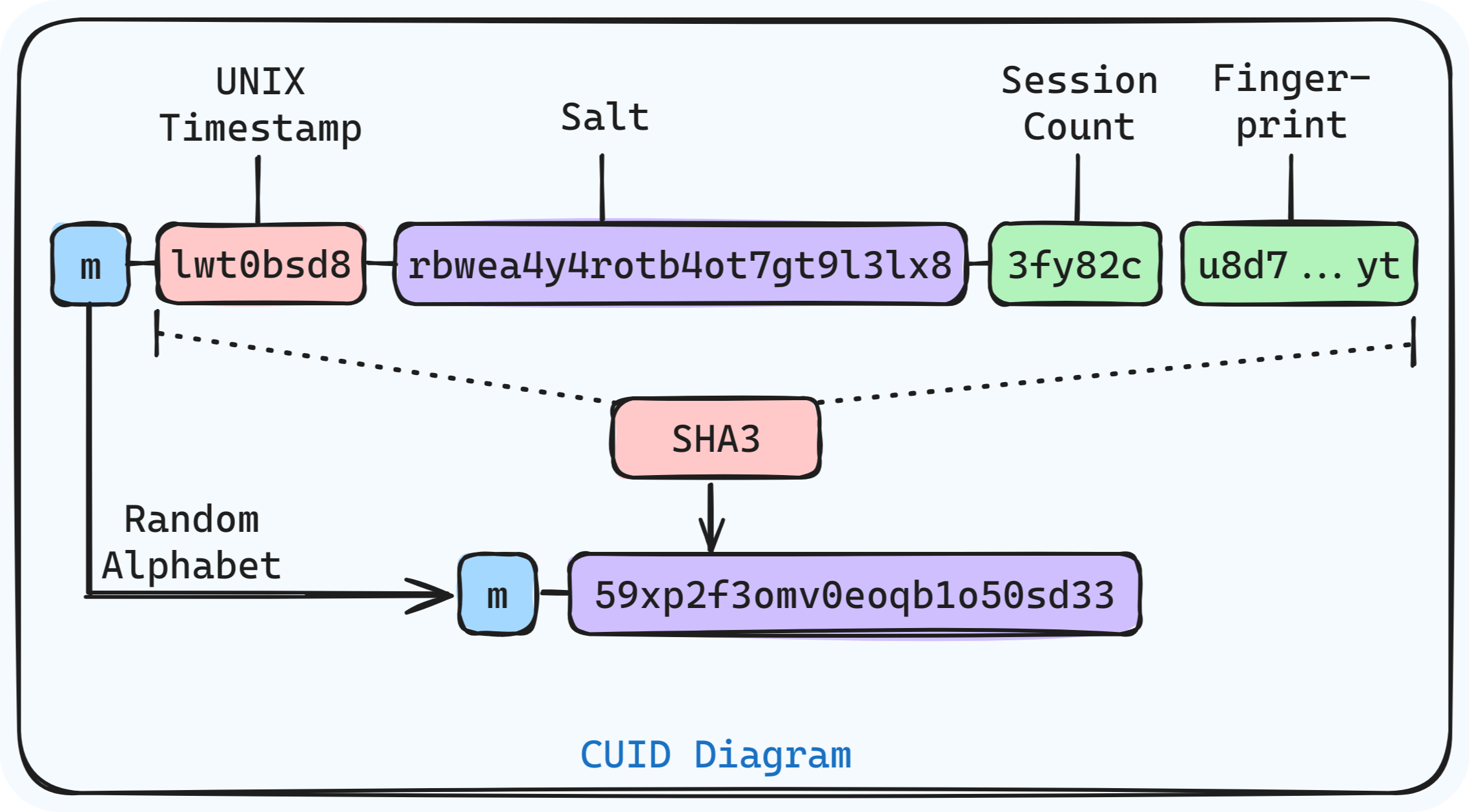
It uses a combination of UNIX time in milliseconds, salt, session count, fingerprint, and hashes these values with the SHA3 hashing algorithm, prefixed by a random alphabet.
Pros
- Strong collision resistance, making it highly unique with the focus on keeping entropy as high as possible to ensure correct randomness.
- Secure, non-guessable, URL-friendly, and supports offline ID generation.
- Horizontally scalable, can generate IDs across multiple machines.
Cons
- It doesn’t work well if sequentiality is in focus.
- Less performant if security and cross-host uniqueness are not priorities.
- Complex due to SHA3 hashing and Pseudorandom Number Generator (PRNG).
NanoId
NanoID is a tiny, secure, URL-friendly, unique string ID generator for JavaScript. With a similar number of random bits, NanoID has similar collision probability to UUID.
NanoID is 21 characters long and ensures unpredictability by using a cryptographic random number generator.
Like CUID, it is possible to configure the length of NanoID.
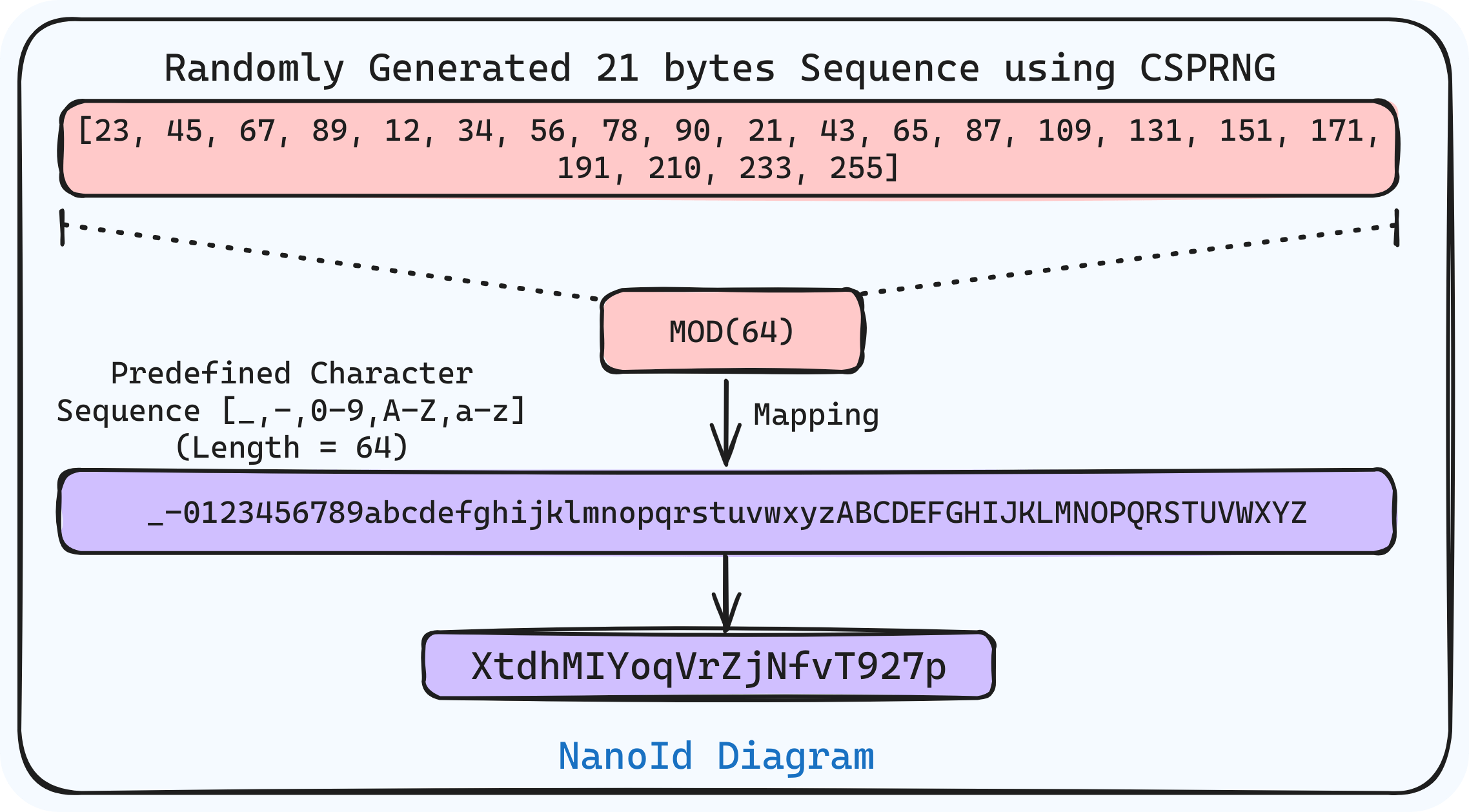
Operation in NanoID
// Randomly Generated 21 bytes Sequence (generated using CSPRNG)
[23, 45, 67, 89, 12, 34, 56, 78, 90, 21, 43, 65, 87, 109, 131, 151, 171, 191, 210, 233, 255]
On each element of the above array, the modulus operation is performed with 64.
// Example
23 % 64 = 23 (character: 'X')
45 % 64 = 45 (character: 't')
67 % 64 = 3 (character: 'd')
and so on...
Pros
- Fast ID generation, compact, and URL-friendly.
- Wide language support and relies on a cryptographic secure number generator (CSPRNG), making it difficult to predict or guess the next ID.
- More storage-efficient compared to UUID.
Cons
- Similar collision probability as UUID, not guaranteeing strong collision resistance.
- Limited information encoding due to reliance on CSPRNG.
- Due to the full dependency on random values, it’s not ideal for applications requiring sequential order, though it is configurable.
Summary
| Functionality / Feature | UUID | ULID | CUID | NanoID |
|---|---|---|---|---|
| Sequentiality / Order | NO | YES | NO | PARTIAL |
| Performance | NO | YES | YES | YES |
| Storage Efficient | NO | YES | YES | YES |
| Collision Resistant | YES | YES | YES | YES |
| Wide Language Support | YES | YES | NO | YES |
| Speed of ID Generation | YES | YES | NO | YES |
| Adoption (Community) | YES | NO | YES | YES |
Note: For highly critical systems where security is a top priority, CUID might be a better choice because it’s harder to guess the next ID. It uses SHA3 and CSPRNG to make IDs more random and unpredictable. If security isn’t the biggest concern, NanoID or other IDs can be good options.
Conclusion
Choosing the right ID system for your application depends on various factors like sequentiality, performance, storage efficiency, collision resistance, and language support. Now that you understand how these IDs work and when to use them, you can make an informed decision for your next project!